剪辑:LRST日本萝莉 porn
【新智元导读】视觉价值模子(VisVM)通过「推理时搜索」来进步多模态视觉言语模子的图像描摹质料,减少幻觉样式。实际标明,VisVM能权贵提高模子的视觉连结身手,并可通过自我教师进一步进步性能。
在当代多模态视觉言语模子(VLM)的发展中,提高图像描摹的准确性和细节丰富性恒久是一个挑战。尽管基于大边界数据的教师极大鼓舞了模子性能,但在实质应用中,模子仍濒临识别轻细图像区域和减少「幻觉」样式的问题。
推理时搜索(inference time search)看成一种进步反应质料的灵验措施,已在大型言语模子中展现出广宽后劲。
O1和QwQ等大言语模子通过在推理阶段在言语空间中进行搜索得到更好的回复,在数学和代码等任务中展现了远独特其他模子的超卓性能。
那么,咱们能否一样通过推理时搜索来进步多模态视觉言语模子的反应质料,并减少反应中的幻觉呢?谜底是是的。
来自马里兰大学和微软的盘考团队建议了视觉价值模子(Vision Value Model, VisVM),通过精准截至搜索历程来权贵提高模子在视觉任务中的弘扬。

论文地址:https://arxiv.org/abs/2412.03704
名目页面:https://si0wang.github.io/projects/VisVM/
名目代码:https://github.com/si0wang/VisVM
VisVM是一种价值集聚,不错通过对逐步生成描摹性标题提供奖励信号来指示视觉言语模子(VLM)在推理时的搜索。
性爱之后模子教师
VisVM最初使用VLM自己生成多个种种化的反应,并将这些反应按照句子维度拆分红next sentence>的sentence pair。
关于每一个current sentence使用CLIP model野心这句话和对应图像的cosine similarity看成reward,临了组成< current sentence, reward,next sentence, Image>的四元组看成VisVM的教师数据。
VisVM使用强化学习中的时序差分学习(Temporal Difference learning)看成示寂函数进行教师。这使得VisVM不仅不错评估现时句子与图像之间的匹配进程,还不错忖度现时句子奈何影响明天句子的生成,为搜索提供一个耐久价值信号。
VisVM开导下的推理阶段搜索:
在教师好VisVM之后,作家使用VisVM看成奖励信号来逐步精细化推理历程。这一历程包括以下几个相貌:
1. 生成多个句子候选:最初,模子会生成多个可能的句子,看成反应的候选。
2. 通过VisVM进行评估:接下来,诓骗VisVM对这些候选句子进行玄虚评估,检修其与图像内容的匹配度以及对明天生成句子的潜在影响(句子中包含的幻觉,细致进程等)。
3. 选拔最好句子:说明VisVM的评估,从候选中挑选出最优的句子来络续生成。
比较于径直使用只研讨现时句子与图像匹配进程的clip分数看成奖励信号进行搜索,VisVM不错进一步通过研讨后续生成的句子中的潜在幻觉来忖度耐久价值,使得VisVM约略遁藏具有更高幻觉风险的反应候选,并生成不易产生幻觉且更详细的图像描摹。
通过这种迭代的推理历程,VLM约略构建出完好且高质料的反应序列,灵验减少信息遗漏和幻觉失实,权贵进步模子的应用性能。
实际
盘考东说念主员摄取LLaVA-Next-Mistral-7B看成实际的基础模子,通过在其encoder的临了一层添加一个线性层看成value head,构建了VisVM并基于这个结构使用上文中构造的数据集与示寂函数进行教师。
在后续的实际中,均使用LLaVA-Next-Mistral-7B看成base model用于生成反应。
盘考东说念主员最初评估了使用不同解码方式生成的反应质料,作家从COCO2017数据聚会采样了1000个图像,并与llava detailed description 数据聚会用于图像描摹的9个prompt进行了随即匹配看成测试集用于生成图像鄙夷。
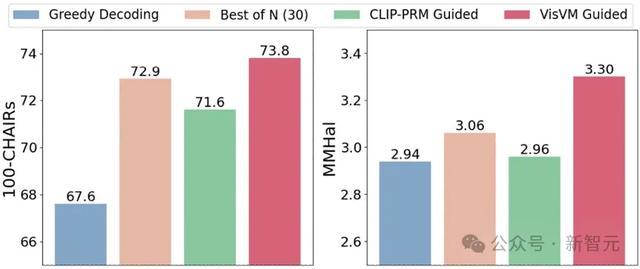
永别使用东说念主类评估和GPT-4o评估,将VisVM开导的搜索与其他老例措施如CLIP-PRM指示搜索、Best-of-N选拔和相关解码得到的图像描摹进行了比较。
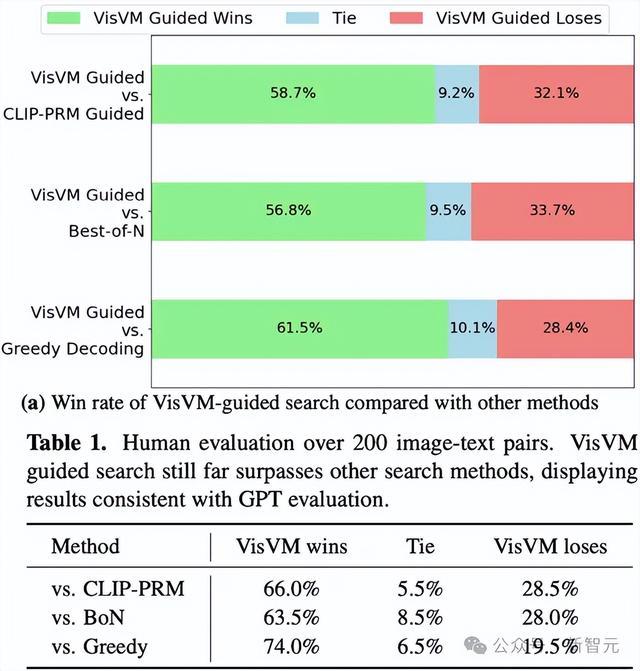
拆伙标明VisVM在生成图像描摹时不仅细节更为丰富,产生的幻觉也大幅减少,其生成的描摹性内容愈加受到evaluator的喜爱。
尤其是在东说念主类看成评估者的情况下,VisVM开导搜索得到的图像描摹比较于其他三个措施永别赢得了66.0%, 63.5%和74.0%的得胜比率。
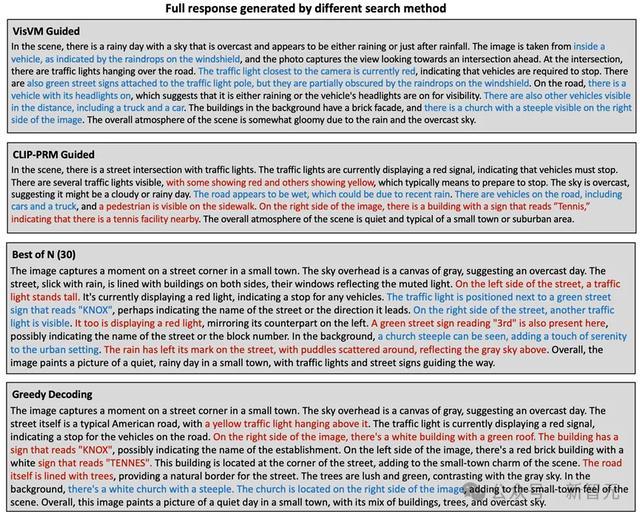
举例,在描摹这个场景时,VisVM开导的搜索以致不错描摹出挡风玻璃上的水点挡住了绿色指令牌,这种细节在东说念主类标注的时候以致齐难以察觉。展示了视觉价值模子关于细节描摹的坚硬身手。

在现存幻觉的benchmark中,盘考东说念主员在VLM的inference阶段使用了非搜索方式生成反应用于评估。
在CHAIR和MMHal两个用于测试VLM幻觉的benchmark上VisVM开导的搜提真金不怕火得了权贵优于其他措施的效能,展示出减少VLM生成反应中的幻觉的坚硬身手
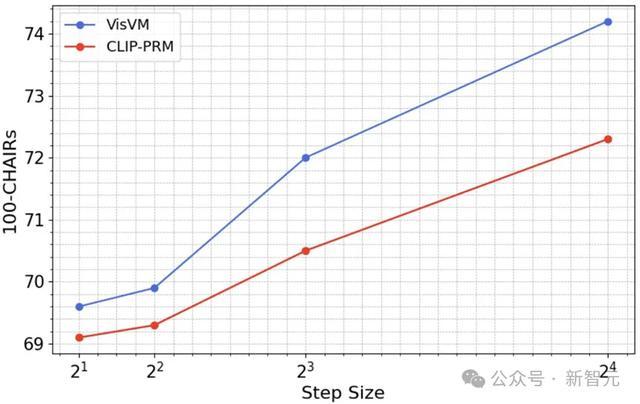
何况,作家还进一步探索明显VisVM开导搜索的scaling law,解发放现不管是摄取VisVM开导的搜索依然CLIP-PRM开导的搜索,跟着搜索相貌大小的加多,模子的性能齐会逐步进步。这一样式解释了扩大推理技术的野心量约略权贵增强VLM的视觉连结身手。
终点值得把稳的是,跟着相貌大小的加多,VisVM开导搜索的性能进步速率更快,使得两种措施之间的性能差距不停扩大。VisVM在达到与CLIP-PRM十分的性能时,其野心效能险些是后者的两倍。
通过扩大搜索相貌,VisVM不仅能更快地达到梦想的性能,还能以更低的野心老本完毕,这在进步模子贬责复杂视觉任务时尤为伏击。
基于VisVM坚硬的减少幻觉的身手,作家使用使用LLaVA-NEXT-Mistral-7B看成基础模子,并诓骗VisVM看成奖励信号,搜索生成高质料的图像描摹看成监督微调(SFT)数据,对LLaVA-NEXT-Mistral-7B进行教师。
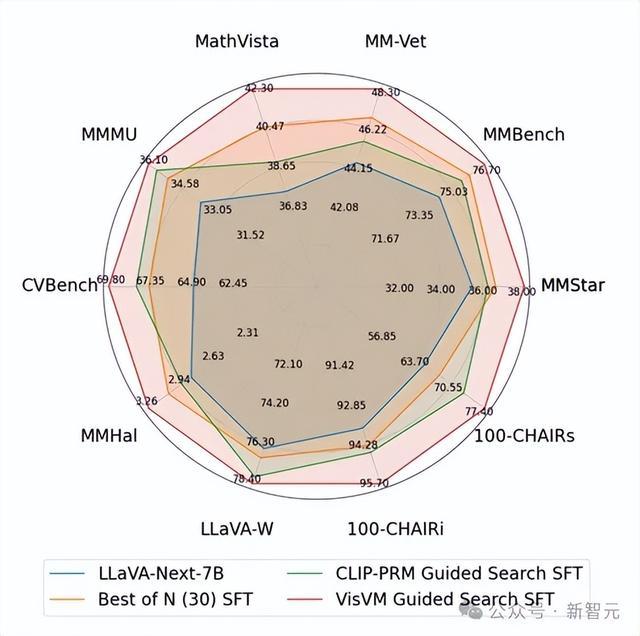
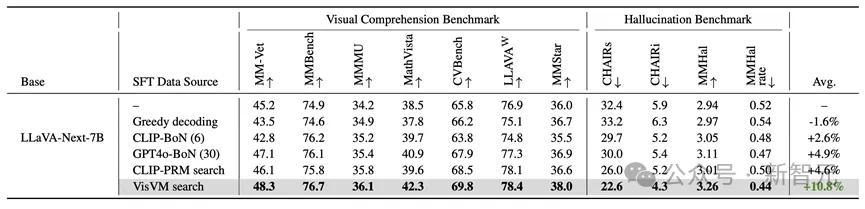
在九个连结和幻觉基准上的测试标明,VisVM开导的自我教师使LLAVA-next-7B的性能平均进步了10.8%,比较于其他搜索措施得到的图像描摹看成教师数据进步权贵。
终点是在进步了视觉连结身手后,VLM的reasoning身手也有所提高,举例MMMU和MathVista两个benchmark,该拆伙进一步展示了VisVM搜索得到的图像描摹质料之高。
此外,这也揭示了VisVM在自我教师框架中的应用后劲,仅通过在言语空间中进行高质料搜索并进行微调,就能权贵进步原始VLM的视觉连结身手,这一发现为明天VLM的发展提供了新的标的和想路。